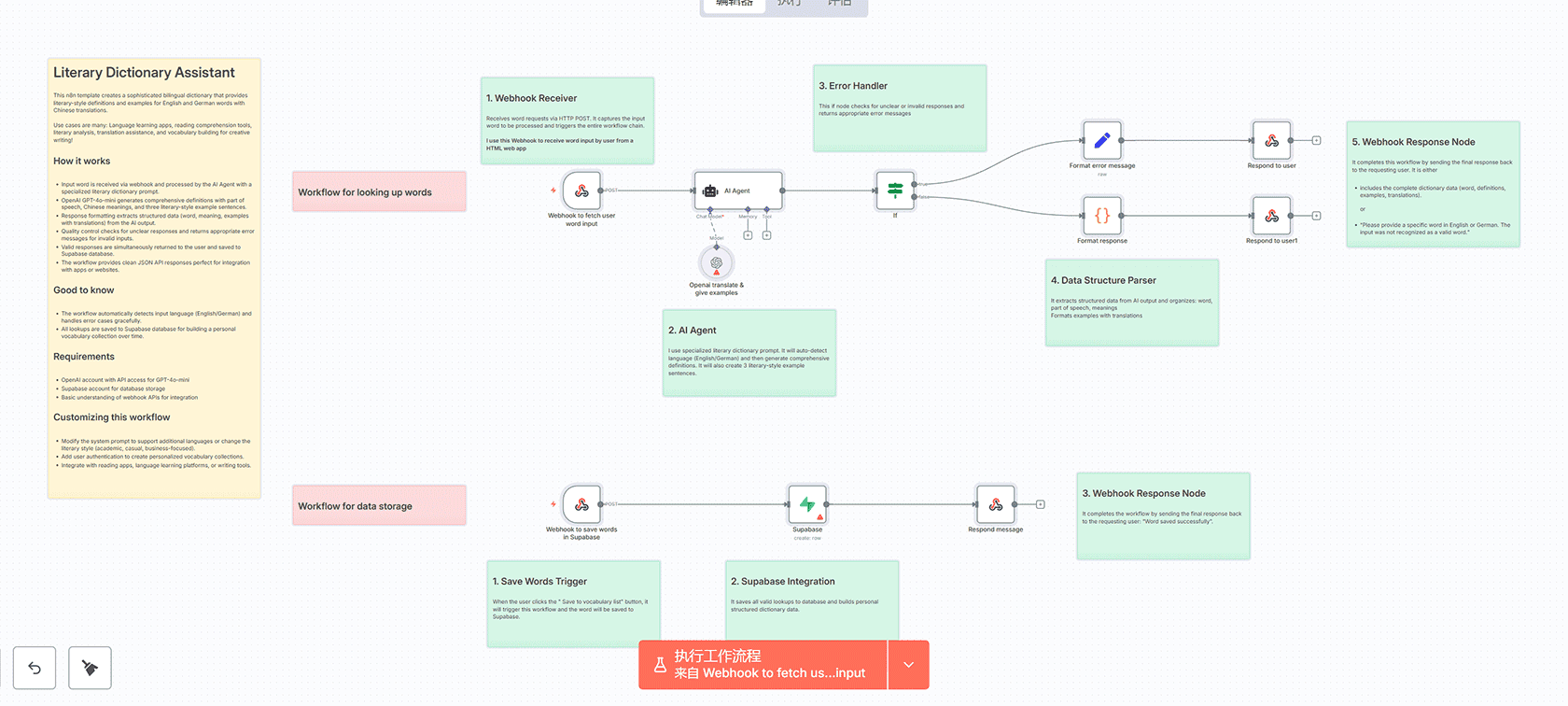
## 概述
这个n8n工作流创建了一个复杂的双语词典,为英语和德语单词提供文学风格的定义和例句。系统自动检测输入语言,生成中文的全面定义,创建三个文学风格的例句及其翻译,并将所有内容存储在Supabase数据库中供将来参考。
## 适用人群
– **语言学习者和学生**:适合学习英语或德语,希望在中文翻译的文学语境中理解单词的人
– **作家和内容创作者**:适合使用英语、德语和中文的双语作家,需要丰富的文学例句进行创作
– **教育工作者和翻译人员**:适合语言教师和专业翻译人员,需要带有上下文例句的全面单词定义
– **文学爱好者**:适合阅读文学作品的读者,遇到不熟悉的单词时想要理解其诗意或文学用法
## 解决的问题
传统词典通常提供基本定义而缺乏文学语境或跨语言例句。这个工作流解决了几个关键挑战:
– **有限的文学语境**:大多数词典缺乏诗意、表达性或文学风格的例句,这些例句有助于理解单词在复杂写作中的用法
– **跨语言学习**:在英语/德语和中文之间提供无缝翻译,并配有文化上合适的例句
– **数据持久化**:自动将所有查找保存到数据库,随时间推移创建个性化的词汇集合
– **API可访问性**:提供干净的webhook接口,可以集成到应用程序、网站或其他工具中
## 工作原理
### 主要词典查找流程
1. **输入处理**:通过webhook POST请求接收单词,自动检测是英语还是德语
2. **AI分析**:使用OpenAI GPT-4o-mini生成带有文学语境的全面定义
3. **响应格式化**:处理AI响应以提取结构化数据(单词、含义、例句)
4. **质量控制**:验证响应并优雅地处理不明确或无效的输入
5. **数据库存储**:将单词、中文含义和例句保存到Supabase供将来参考
6. **API响应**:返回格式化的JSON,包含完整的词典条目
### 数据存储流程
– **并行处理**:同时向用户返回词典数据并将其保存到数据库
– **结构化存储**:在Supabase中组织数据,包含单词、中文含义和例句数组的字段
– **成功确认**:数据成功存储时提供确认
## 设置说明
### 先决条件和账户
您需要以下账户和API访问权限:
– n8n(云或自托管)
– OpenAI(需要API密钥)
– Supabase(数据库和API凭据)
### Webhook配置
– 工作流使用两个具有相同路径的webhook端点进行不同操作
– 记下n8n提供的webhook URL以进行API集成
– 测试webhook端点以确保它们可访问
## 自定义选项
– 通过修改AI提示扩展以支持其他输入语言
– 添加对中文以外的其他目标语言的支持
– 为不同的文化语境自定义文学风格
这个工作流将简单的单词查找转变为丰富的、上下文相关的学习体验,同时随时间推移构建个性化的词汇数据库。
评论(0)