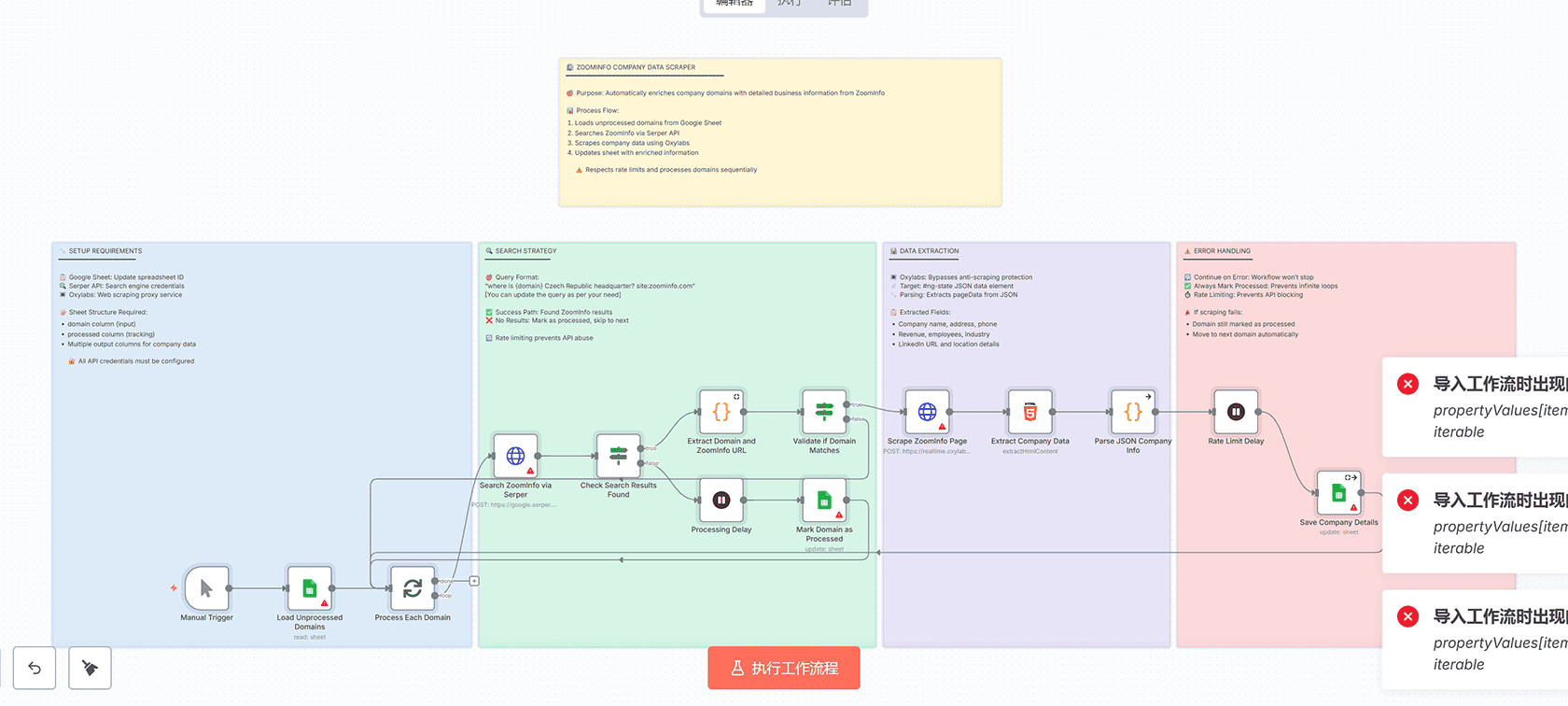
## 工作流概述
这个n8n工作流专门用于自动从ZoomInfo抓取和丰富公司数据信息。通过整合多个API服务,工作流能够将简单的域名列表转化为包含详细业务信息的结构化数据,为销售团队、市场研究人员和业务开发团队提供准确的潜在客户信息。
## 目标用户
– **销售团队**:构建包含准确公司信息的潜在客户数据库
– **市场专业人员**:为目标公司的营销活动进行调研
– **业务开发团队**:使用收入和员工数据来筛选潜在客户
– **研究人员**:为市场分析收集结构化公司数据
– **潜在客户生成专家**:用联系信息丰富域名列表
## 工作原理
工作流从Google Sheets加载未处理的域名,使用Serper API搜索它们的ZoomInfo个人资料,通过Oxylabs代理服务抓取公司页面,并提取结构化业务数据。每个域名都被标记为已处理以防止重复,工作流包含适当的速率限制以遵守API限制。
## 主要功能
– 从Google Sheets数据库加载未处理的域名
– 通过Serper API使用有针对性的查询搜索ZoomInfo
– 验证搜索结果并提取相关的ZoomInfo个人资料URL
– 使用Oxylabs抓取公司页面以绕过反抓取保护
– 提取结构化数据,包括公司详细信息、地址、收入和员工数量
– 使用丰富的公司信息更新Google Sheets
– 跟踪处理状态以防止重复处理相同的域名
## 技术节点组成
工作流包含以下核心节点:
1. **Manual Trigger** – 手动触发工作流执行
2. **Google Sheets** – 从电子表格加载未处理的域名
3. **Split In Batches** – 批量处理域名
4. **HTTP Request** – 通过Serper API搜索ZoomInfo
5. **If** – 检查搜索结果是否找到
6. **Code** – 提取域名和ZoomInfo URL
7. **HTML** – 提取公司数据内容
8. **Wait** – 速率限制延迟
9. **Error Handling** – 错误处理和继续执行
## 输出数据
– 完整的公司名称和官方地址
– 电话号码和联系信息
– 收入数字和员工人数
– 行业分类和业务类别
– LinkedIn公司个人资料URL
– 地理位置详细信息(城市、州、国家、邮政编码)
– 处理状态跟踪用于工作流管理
## 设置要求
– Serper API账户(获取API密钥)
– Oxylabs订阅用于网络抓取代理服务
– Google Sheets API访问权限,使用OAuth2身份验证
– Google Sheets模板 – 复制此模板表格,其中包含预配置的列
## 自定义选项
– **搜索查询修改**:更新Serper节点中的搜索查询以关注不同的地理区域(当前设置为捷克共和国)
– **数据提取字段**:修改Google Sheets列映射以包含/排除特定的公司数据点
– **速率限制**:调整请求之间的等待时间以匹配您的API速率限制
– **批处理**:配置拆分批次大小以处理较小的域名组
– **错误处理**:根据您的数据质量要求自定义继续错误设置
– **调度**:将手动触发器替换为计划触发器以进行自动每日/每周运行
## 技术特点
该工作流包含全面的错误处理,确保域名始终被标记为已处理,防止无限循环,同时保持数据完整性。内置速率限制以遵守API配额并避免服务中断。
评论(0)