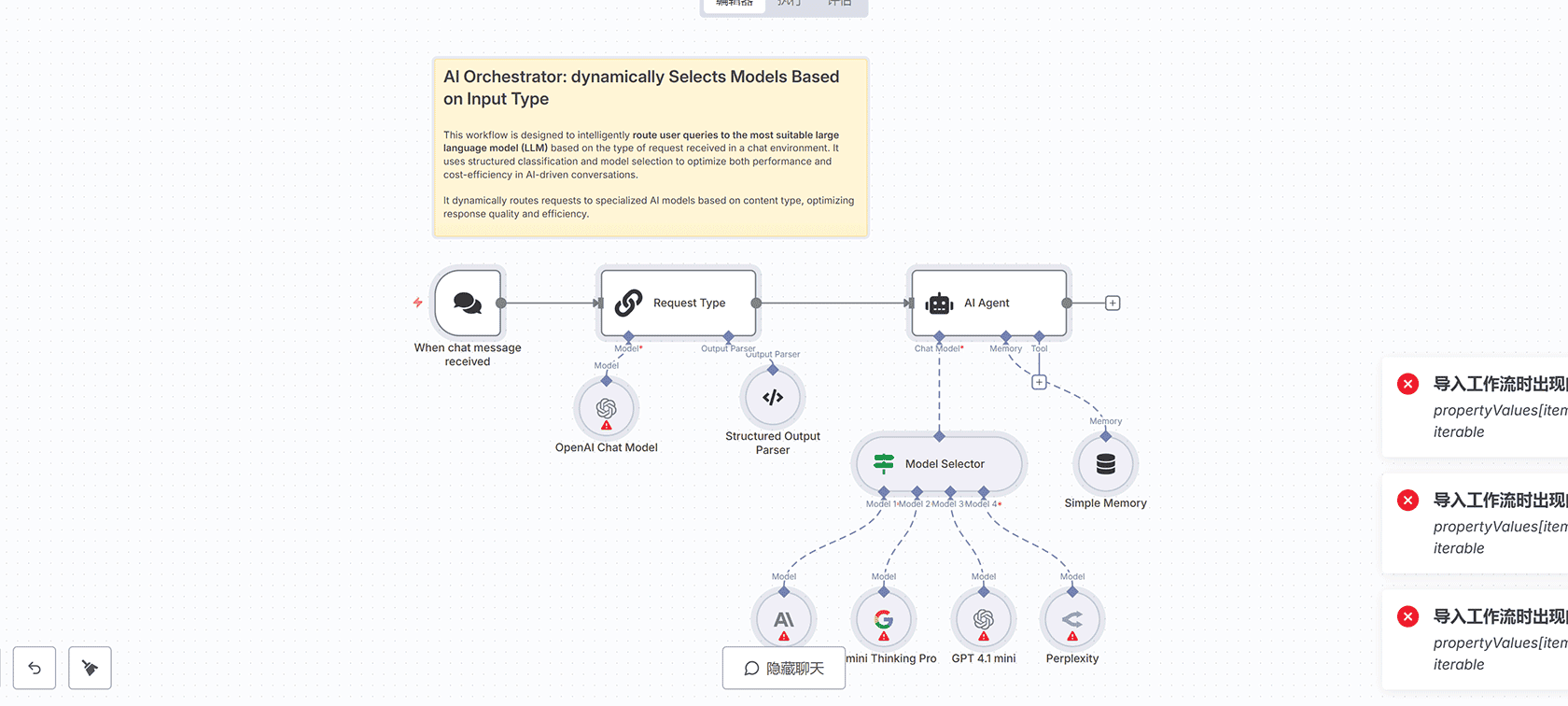
## 工作流概述
这个工作流旨在智能地将用户查询路由到最适合的大型语言模型(LLM),根据在聊天环境中接收到的请求类型进行优化。它使用结构化分类和模型选择来优化AI驱动对话的性能和成本效率。
## 工作原理
### 输入处理
工作流从”When chat message received”节点开始,当接收到聊天消息时触发流程。输入包括聊天消息(chatInput)和会话ID(sessionId)。
### 请求分类
“Request Type”节点使用OpenAI模型(gpt-4.1-mini)将传入请求分类为以下四个类别之一:
– general:用于一般查询
– reasoning:用于基于推理的问题
– coding:用于代码相关请求
– search:用于需要搜索工具的查询
分类使用”Structured Output Parser”节点进行结构化,该节点强制执行一致的输出格式。
### 模型选择
“Model Selector”节点根据分类将请求路由到四个AI模型之一:
– Opus 4(Claude 4 Sonnet):用于编码请求
– Gemini Thinking Pro:用于推理请求
– GPT 4.1 mini:用于一般请求
– Perplexity:用于搜索(Google相关)请求
### AI处理
选定的模型通过”AI Agent”节点处理请求,该节点包括复杂任务的中间步骤。”Simple Memory”节点使用提供的sessionId保留会话上下文,实现多轮对话。
### 输出
最终响应由选定的模型生成并返回给用户。
## 设置步骤
### 配置触发器
确保”When chat message received”节点设置了正确的webhook ID以接收聊天输入。
### 定义分类逻辑
调整”Request Type”节点中的提示以提高分类准确性。验证”Structured Output Parser”节点中的输出模式是否匹配预期类别(general、reasoning、coding、search)。
### 连接AI模型
将每个模型节点(Opus 4、Gemini Thinking Pro、GPT 4.1 mini、Perplexity)连接到”Model Selector”节点。确保每个模型在各自节点中的凭据(API密钥)正确配置。
### 设置内存
配置”Simple Memory”节点使用输入中的sessionId进行上下文保留。
### 测试工作流
发送测试输入以验证分类和模型路由。检查中间输出(例如request_type)以确保正确的模型选择。
### 激活工作流
测试后在n8n中将工作流切换为”Active”。
## 优势
– **智能模型路由**:通过为一般任务使用较轻的模型和为复杂需求保留较重的模型来降低成本
– **可扩展性**:通过添加更多请求类型或LLM轻松扩展
– **可维护性**:分类、模型路由和执行之间的清晰逻辑分离
– **个性化**:可以与会话ID集成以实现每用户内存,实现个性化对话
– **速度优化**:为优先考虑速度的任务选择GPT-4.1 mini或Gemini Flash等快速模型
评论(0)