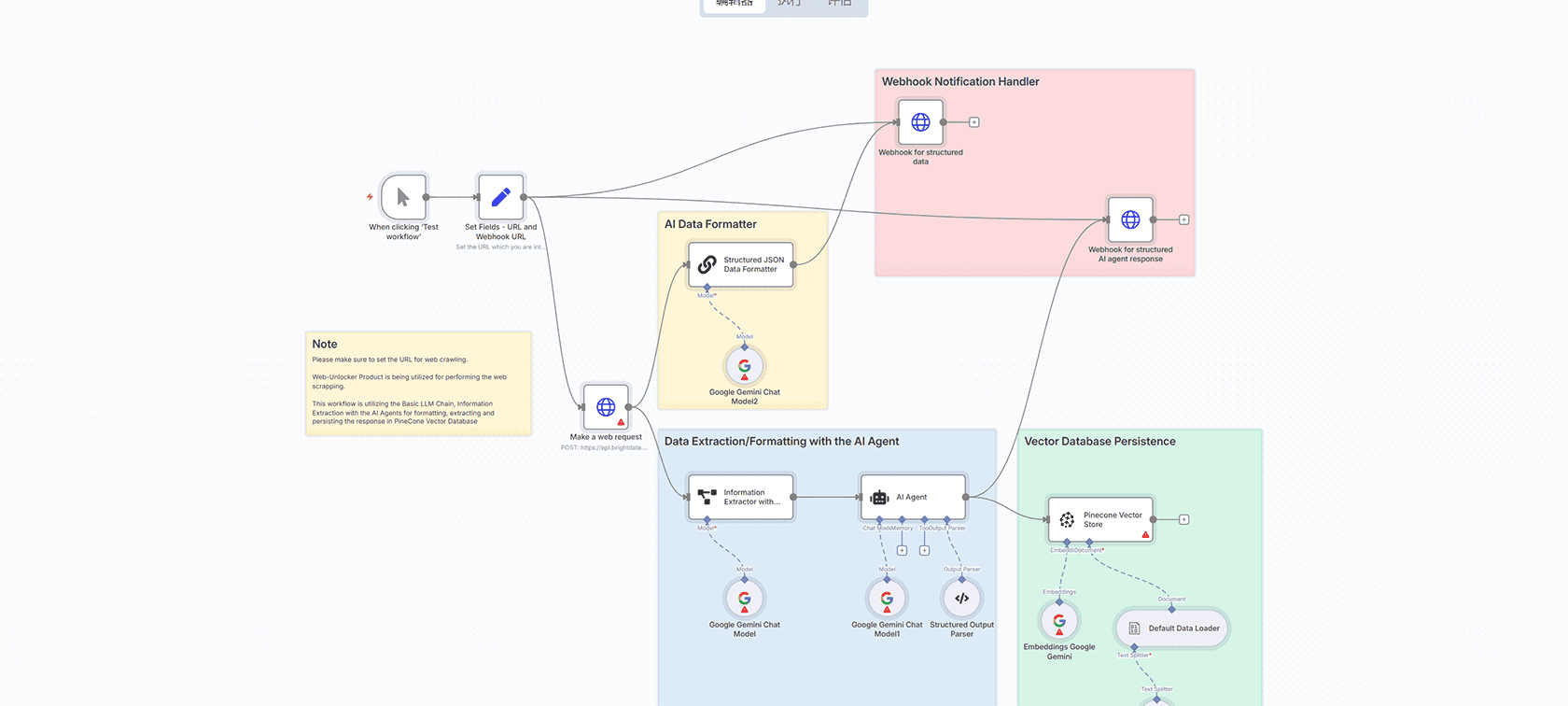
LinkedIn公司故事生成器是一个自动化工作流,它使用Bright Data的网络抓取基础设施从LinkedIn提取公司档案数据,然后使用语言模型(如OpenAI、Gemini)将这些数据转换为专业撰写的叙述或故事。最终输出通过webhook通知发送,便于发布、审查或进一步自动化。
该工作流适用于:
营销专业人士:寻求为营销活动生成引人入胜的公司叙述。
销售团队:旨在通过汇总的公司洞察了解潜在客户。
内容创作者:希望基于公司数据制作故事或文章。
招聘人员:对获取公司简明概述以用于人才获取策略感兴趣。
该工作流解决的问题:
从LinkedIn手动收集和汇总公司信息可能耗时且不一致。该工作流自动化了此过程,确保:
效率:快速提取和汇总公司数据。
一致性:标准化汇总,确保跨用例的统一性。
可扩展性:能够处理多个公司而无需额外的手动工作。
该工作流执行以下步骤:
输入获取:接收公司名称或LinkedIn URL作为输入。
数据提取:使用Bright Data抓取公司的LinkedIn档案。
信息解析:处理提取的HTML内容以检索相关公司详细信息。
汇总:使用AI Google Gemini生成简洁的公司故事。
输出交付:将汇总内容发送到指定的webhook或电子邮件地址。
设置
在Bright Data注册。
导航到Proxies & Scraping,在Scraping Solutions下选择Web Unlocker API,创建一个新的Web Unlocker区域。
在n8n中,在Credentials下配置Header Auth账户(Generic Auth Type:Header Authentication)。
Value字段应设置为Bearer XXXXXXXXXXXXXX。XXXXXXXXXXXXXX应替换为Web Unlocker Token。
在n8n中,使用Google Gemini API密钥配置Google Gemini(PaLM) Api账户(或通过Vertex AI或代理访问)。
通过导航到Set LinkedIn URL节点更新LinkedIn URL。
使用您选择的Webhook端点更新Webhook HTTP Request节点。
如何根据您的需求自定义此工作流
输入变化:修改Set LinkedIn URL节点以接受不同的公司LinkedIn URL。
数据点:调整HTML Data Extractor节点以检索其他详细信息,如员工数量、行业或总部位置。
汇总风格:自定义AI提示以生成不同语气或格式的汇总(例如,正式、随意、项目符号)。
输出目的地:配置输出节点以将汇总发送到各种平台,如Slack、CRM系统或数据库。
评论(0)