免责声明
Execute Command节点仅在自托管(本地)n8n实例中受支持。
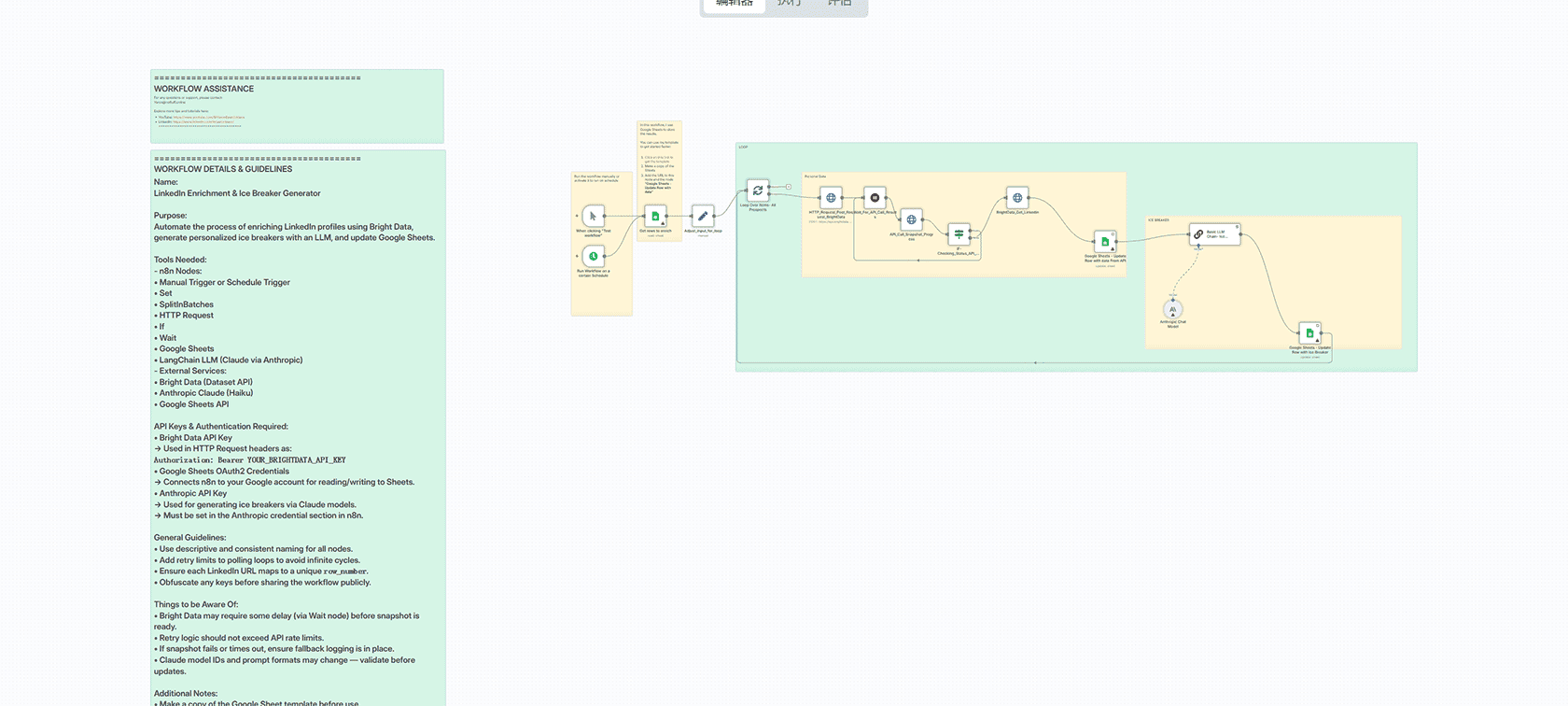
介绍
KOKORO TTS – Kokoro TTS是一个紧凑而强大的文本转语音模型,目前在Hugging Face和GitHub上可用。尽管其规模适中——在不到100小时的音频上训练——但它提供了令人印象深刻的结果,在Hugging Face的TTS排行榜上始终名列前茅。与较大的系统不同,Kokoro TTS具有在本地运行的优势,即使在无GPU的设备上也能运行,使其适用于广泛的用户。
谁将从这个集成中受益?
这对视频博主、TikTok用户很有用,并且还将能够创建免费的语音聊天机器人。目前,TTS模型大多是付费的,但这个集成将允许完全免费的语音生成。可能性仅受您的想象力限制。
注意
不幸的是,我们无法通过浏览器URL(GET/POST)与KOKORO API交互,但我们可以通过n8n运行Python脚本并将任何变量传递给它。
在教程中,使用了D盘,但您可以为任何路径重写此内容,包括C盘。
步骤1
您需要安装Python。链接
此外,从GitHub下载并解压缩Kokoro的便携版本。
在KOKORO文件夹中创建一个名为voicegen.py的文件:(C:\KOKORO)。如您所见,输出路径为:(D:\output.mp3)。
import sys
import shutil
from gradio_client import Client
# 为stdout设置UTF-8编码
sys.stdout.reconfigure(encoding=’utf-8′)
# 从命令行获取参数
text = sys.argv[1] # 第一个参数:输入文本
voice = sys.argv[2] # 第二个参数:语音
speed = float(sys.argv[3]) # 第三个参数:速度(转换为浮点数)
print(f”接收到的文本:{text}”)
print(f”语音:{voice}”)
print(f”速度:{speed}”)
# 连接到本地Gradio服务器
client = Client(“http://localhost:7860/”)
# 使用API生成语音
result = client.predict(
text=text,
voice=voice,
speed=speed,
api_name=”/generate_speech”
)
# 定义输出路径
output_path = r”D:\output.mp3″
# 移动生成的文件
shutil.move(result[1], output_path)
# 打印输出路径
print(output_path)
步骤2
转到n8n并创建以下工作流。
步骤3
编辑字段模块。
{
“voice”: “af_sarah”,
“text”: “Hello world!”
}
步骤4
我们将需要一个带有命令的Execute Command模块:python
C:\KOKORO\voicegen.py “{{ $json.text }}” “{{ $json.voice }}” 1
步骤5
脚本已经在工作,但要收听它,您可以连接一个带有生成的MP3文件路径的Binary模块
D:/output.mp3
步骤6
单击”Text workflow”并享受结果。
有比ChatGPT更多的语音和口音,而且是免费的。
附注
如果您需要,我的博客上有详细的教程。
评论(0)