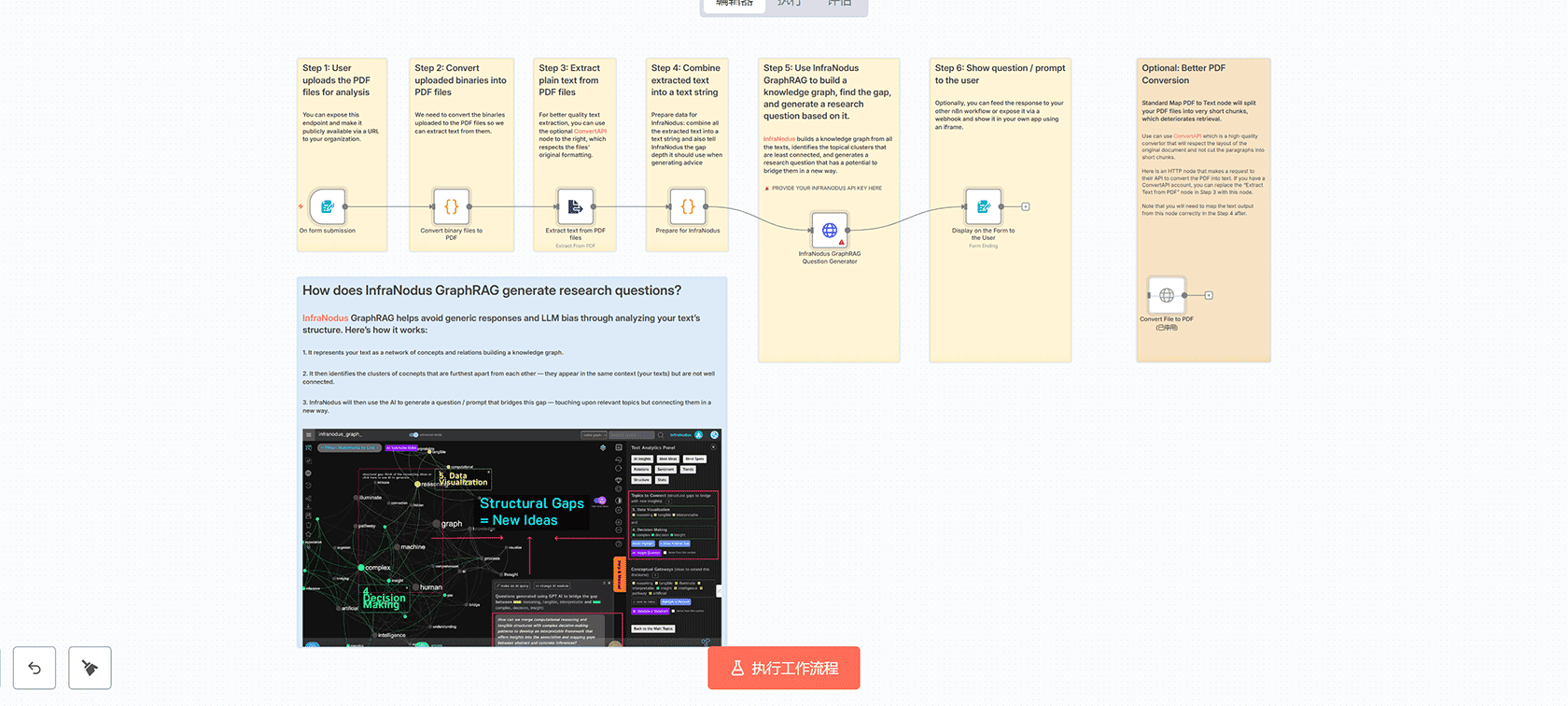
## 工作流概述
这个n8n工作流模板能够从PDF文档(如研究论文、市场报告)中基于内容差距生成研究问题和AI提示。通过使用InfraNodus知识图谱GraphRAG技术,该模板可以分析文本中的结构差距,并生成能够推动研究前进的创新性问题。
## 主要功能
– **生成研究问题**:基于文档内容的结构性差距生成有针对性的研究问题
– **生成AI提示**:创建能够驱动进一步研究的AI提示
– **发现盲点**:识别任何论述中的盲点并生成解决这些盲点的想法
– **避免通用偏见**:避免LLM模型的通用偏见,专注于特定上下文中的重要内容
## 工作原理
### 知识图谱表示
知识图谱将任何文本表示为网络:主要概念是节点,它们的共现是节点之间的连接。基于这种表示,构建一个图谱并应用网络科学指标来排名最重要的节点(概念),这些节点作为意义的十字路口,同时也连接主要主题聚类。
### 内容差距识别
自然地,一些聚类将是断开的,它们之间存在差距。这些是在您的上下文(上传的文档)中存在但连接不佳的主题(概念组)。解决这些差距可以帮助您看到哪些概念组可以通过您自己的想法连接起来。
## 工作流程步骤
### 第1步:表单提交
用户通过在线Web表单上传PDF文件,该表单可以从n8n运行甚至公开可用。
### 第2步:转换为PDF文件
将上传的二进制文件转换为PDF文件以便从中提取文本。
### 第3步:从PDF文件中提取文本
使用PDF到文本节点从文档中提取纯文本。
### 第4步:准备InfraNodus数据
将所有提取的文本组合成文本字符串,并告诉InfraNodus在生成建议时应使用的差距深度。
### 第5步:InfraNodus GraphRAG分析
InfraNodus从所有文本构建知识图谱,识别连接最少的主题聚类,并生成有可能以新方式桥接它们的研究问题。
### 第6步:向用户显示问题/提示
将响应提供给用户,或将其提供给其他n8n工作流。
## 如何使用
### 要求
– InfraNodus账户和API密钥
– 不需要OpenAI密钥,通过API密钥直接访问InfraNodus AI
### 设置步骤
1. 创建InfraNodus账户
2. 在https://infranodus.com/api-access获取API密钥并创建Bearer授权密钥
3. 将此密钥添加到在此工作流中使用的InfraNodus GraphRAG HTTP节点中
## 自定义选项
– 可以使用Telegram机器人或Slack(接收摘要和想法的通知)
– 可以在此模板的末尾连接自动社交媒体内容创建工作流
– 可以生成相关(涵盖您利基中的重要主题)且新颖(因为它们以新方式连接它们)的帖子
## 技术优势
这种方法通过分析文本结构帮助避免通用响应和LLM偏见,确保生成的问题既相关又具有创新性。
评论(0)