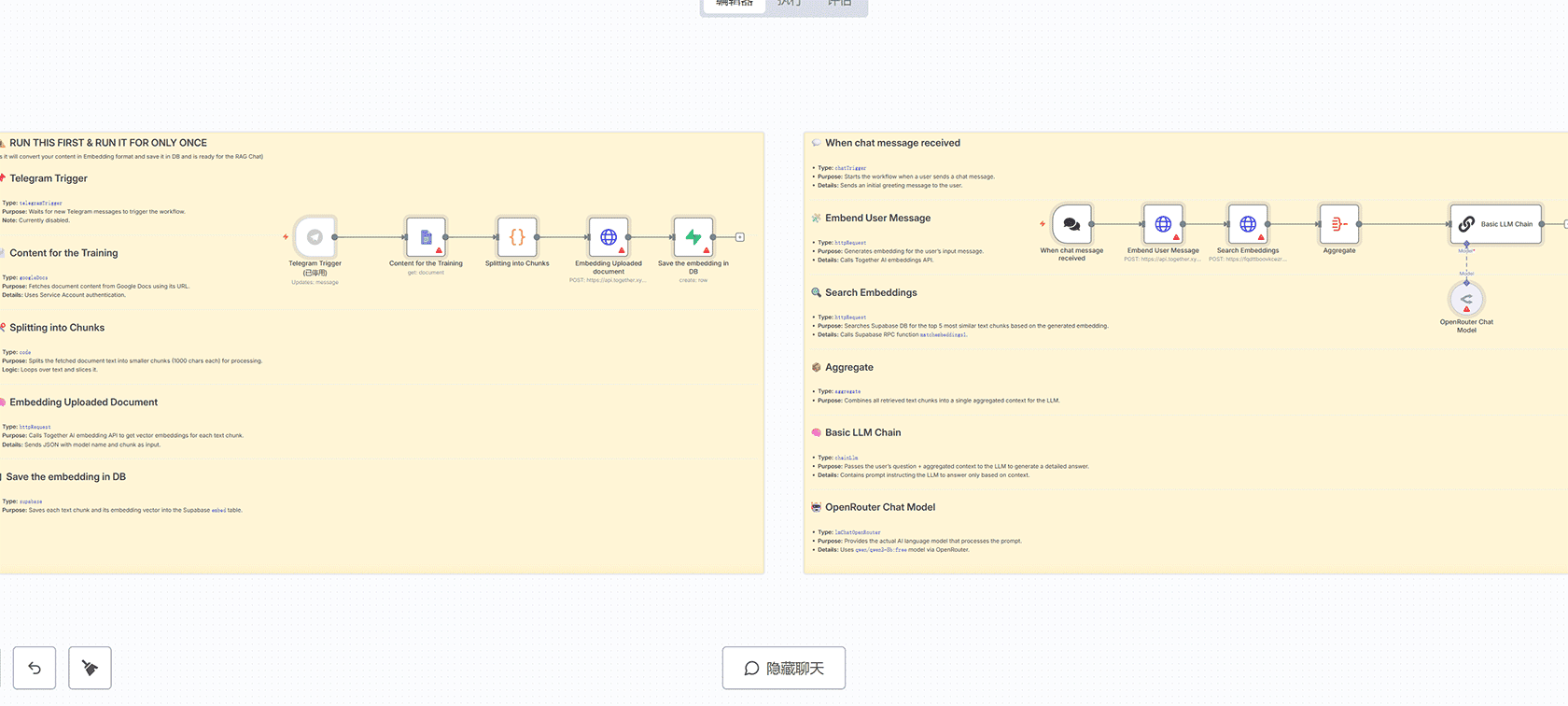
## 工作流概述
这是一个基于检索增强生成(RAG)技术的智能聊天机器人工作流,使用n8n平台构建。该工作流分为两个主要部分:文档训练阶段和聊天响应阶段。
## 第一阶段:文档训练流程
### 📌 Telegram触发器
– **类型**: `telegramTrigger`
– **功能**: 等待新的Telegram消息来触发工作流
– **状态**: 当前已禁用
### 📄 训练内容获取
– **类型**: `googleDocs`
– **功能**: 使用Google Docs URL获取文档内容
– **认证**: 服务账户认证
### ✂️ 文本分块处理
– **类型**: `code`
– **功能**: 将获取的文档文本分割成较小的块(每块1000字符)
– **逻辑**: 循环遍历文本并进行切片
### 🧠 文档嵌入生成
– **类型**: `httpRequest`
– **功能**: 调用Together AI嵌入API为每个文本块生成向量嵌入
– **详情**: 发送包含模型名称和文本块的JSON数据
### 🛢 嵌入向量存储
– **类型**: `supabase`
– **功能**: 将每个文本块及其嵌入向量保存到Supabase的embed表中
## 第二阶段:聊天响应流程
### 💬 聊天消息接收
– **类型**: `chatTrigger`
– **功能**: 当用户发送聊天消息时启动工作流
– **详情**: 向用户发送初始问候消息
### 🧩 用户消息嵌入
– **类型**: `httpRequest`
– **功能**: 为用户输入消息生成嵌入向量
– **详情**: 调用Together AI嵌入API
### 🔍 嵌入向量搜索
– **类型**: `httpRequest`
– **功能**: 基于生成的嵌入向量在Supabase数据库中搜索最相似的5个文本块
– **详情**: 调用Supabase RPC函数`matchembeddings1`
### 📦 上下文聚合
– **类型**: `aggregate`
– **功能**: 将所有检索到的文本块组合成单一聚合上下文供LLM使用
### 🧠 基础LLM链
– **类型**: `chainLlm`
– **功能**: 将用户问题+聚合上下文传递给LLM生成详细答案
– **详情**: 包含提示指令,要求LLM仅基于上下文回答
### 🤖 OpenRouter聊天模型
– **类型**: `lmChatOpenRouter`
– **功能**: 提供实际处理提示的AI语言模型
– **详情**: 通过OpenRouter使用`qwen/qwen3-8b:free`模型
## 重要注意事项
⚠️ **仅运行第一个工作流一次**
– 第一个工作流会将内容转换为嵌入格式并保存到数据库中,为RAG聊天做好准备
– 重复运行会导致数据重复
## 技术特点
– **RAG架构**: 结合检索和生成技术,提供基于文档的准确回答
– **向量搜索**: 使用Supabase进行高效的相似性搜索
– **多模型支持**: 可通过OpenRouter使用多种AI模型
– **实时响应**: 支持即时聊天交互
– **可扩展性**: 易于添加新的文档源和模型
评论(0)