## 概述
这个n8n工作流通过监控Kubernetes Pod的CPU使用情况,当CPU消耗超过阈值(例如0.8核心)时,向Slack发送实时告警。它按应用程序名称对Pod进行分组,以减少噪音并提高清晰度,非常适合跨多Pod部署(如Argo CD、Loki、Promtail等)的可观测性。
## 目标用户
专为DevOps、SRE团队和平台团队设计,这个工作流是100%无代码、即插即用的,可以轻松扩展以支持内存、磁盘或网络峰值。它通过使用原生n8n节点将关键告警直接路由到Slack,消除了对Alertmanager的需求。
## 工作流功能
– ⏱️ 每5分钟轮询一次Prometheus
– 🚨 检查是否有任何Pod的CPU使用率超过定义的阈值(例如0.8核心)
– 🧩 按应用程序对Pod进行分组
– 💬 向Slack频道发送结构化告警
## 设置步骤
1. 🔗 设置您的Prometheus URL,包含必需的指标(container_cpu_usage_seconds_total, kube_pod_container_resource_limits)
2. 🔐 添加具有chat:write范围的Slack机器人令牌
3. 🧩 导入工作流并自定义:
– 阈值(例如0.8核心)
– Slack频道
– Cron计划
## 技术要求
– 带有kube-state-metrics的正常运行的Prometheus堆栈
– Slack机器人凭据
– n8n实例(自托管或云)
## 自定义选项
– 🧠 调整阈值或查询间隔
– 📈 添加内存/磁盘/网络使用指标
这是一个用于实时可观测性的即插即用Kubernetes告警模板。
## 工作流节点说明
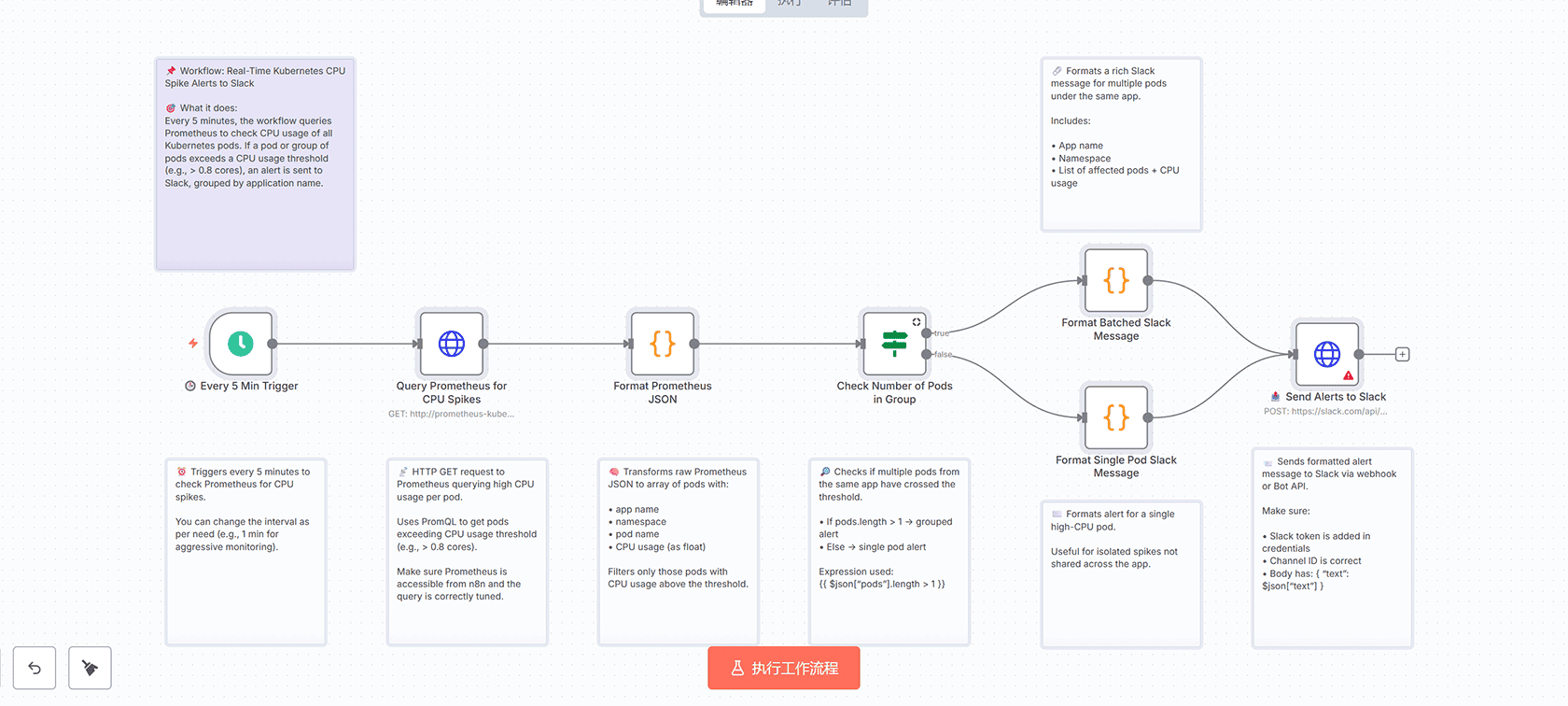
1. **🕒 Every 5 Min Trigger** – 每5分钟触发一次,检查Prometheus的CPU峰值
2. **Query Prometheus for CPU Spikes** – HTTP GET请求查询Prometheus中高CPU使用率的Pod
3. **Format Prometheus JSON** – 将原始Prometheus JSON转换为包含应用程序名称、命名空间、Pod名称和CPU使用率的数组
4. **Check Number of Pods in Group** – 检查同一应用程序下是否有多个Pod超过阈值
5. **Format Batched Slack Message** – 为同一应用程序下的多个Pod格式化批量Slack消息
6. **Format Single Pod Slack Message** – 为单个Pod格式化Slack消息
7. **📤 Send Alerts to Slack** – 通过Webhook或Bot API将格式化后的告警消息发送到Slack
## 标签
Prometheus, Slack, Kubernetes, Alert, n8n, DevOps, Observability, CPU Spike, Monitoring
评论(0)