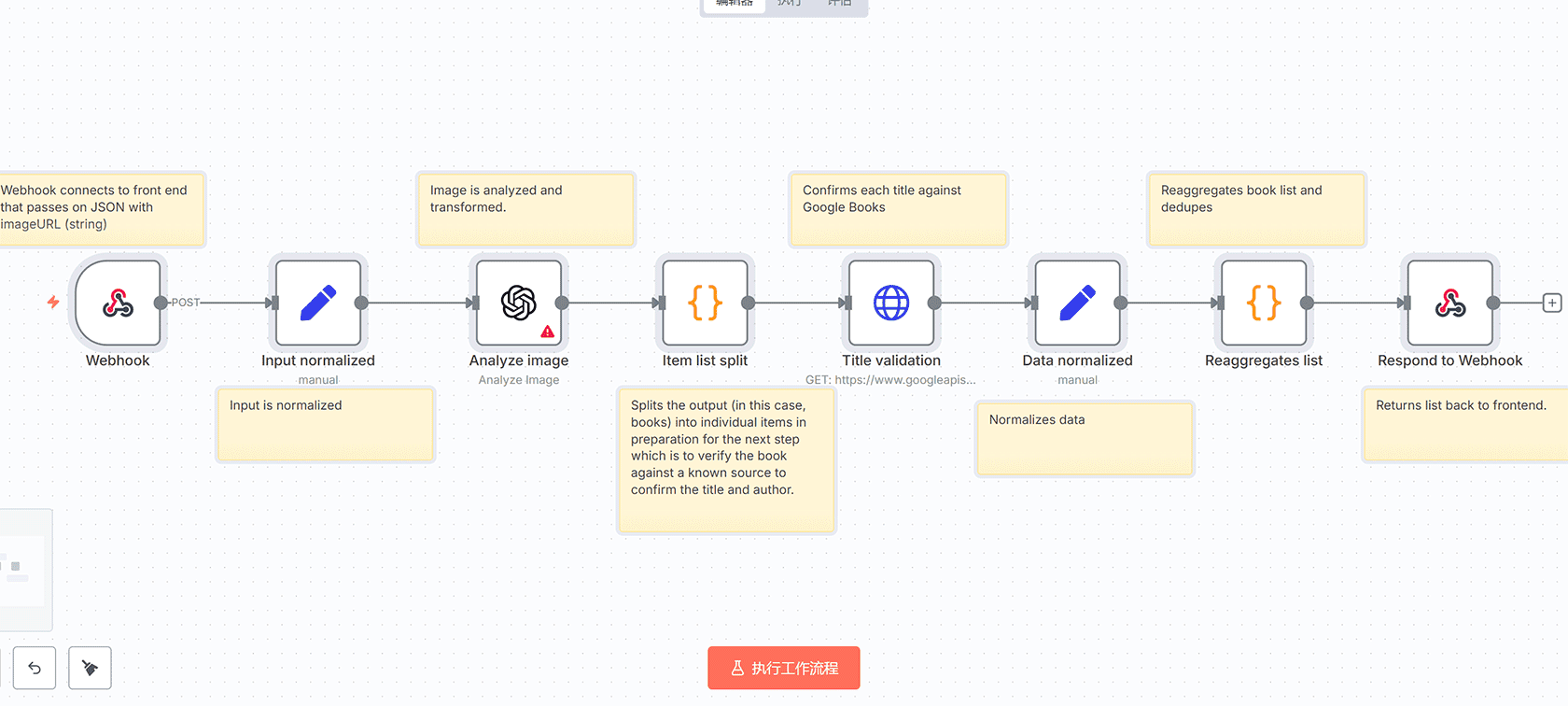
这个n8n工作流是一个智能书籍扫描器,能够自动识别和分析书籍信息。工作流通过以下步骤实现功能:
**工作流程:**
1. **Webhook触发** – 接收前端传递的包含图片URL的JSON数据
2. **输入标准化** – 使用Set节点规范化输入数据,提取图片URL
3. **图像分析** – 通过OpenAI GPT-4o-mini模型分析书籍书脊图像,识别可读的标题和作者信息
4. **数据拆分** – 使用Code节点将识别出的书籍列表拆分为单个项目
5. **标题验证** – 通过HTTP Request节点调用Google Books API验证书籍标题和作者信息
6. **数据标准化** – 再次使用Set节点规范化验证后的数据
7. **列表重新聚合** – 使用Code节点重新聚合书籍列表并去除重复项
8. **响应返回** – 通过Respond to Webhook节点将处理结果返回给前端
**技术特点:**
– 严格的数据验证机制,不猜测模糊信息
– 智能去重功能,避免重复书籍
– 支持作者信息为空的情况
– 与Google Books API集成确保数据准确性
**应用场景:**
– 图书馆自动化管理
– 个人书籍收藏数字化
– 书店库存管理
– 学术研究资料整理
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。
评论(0)