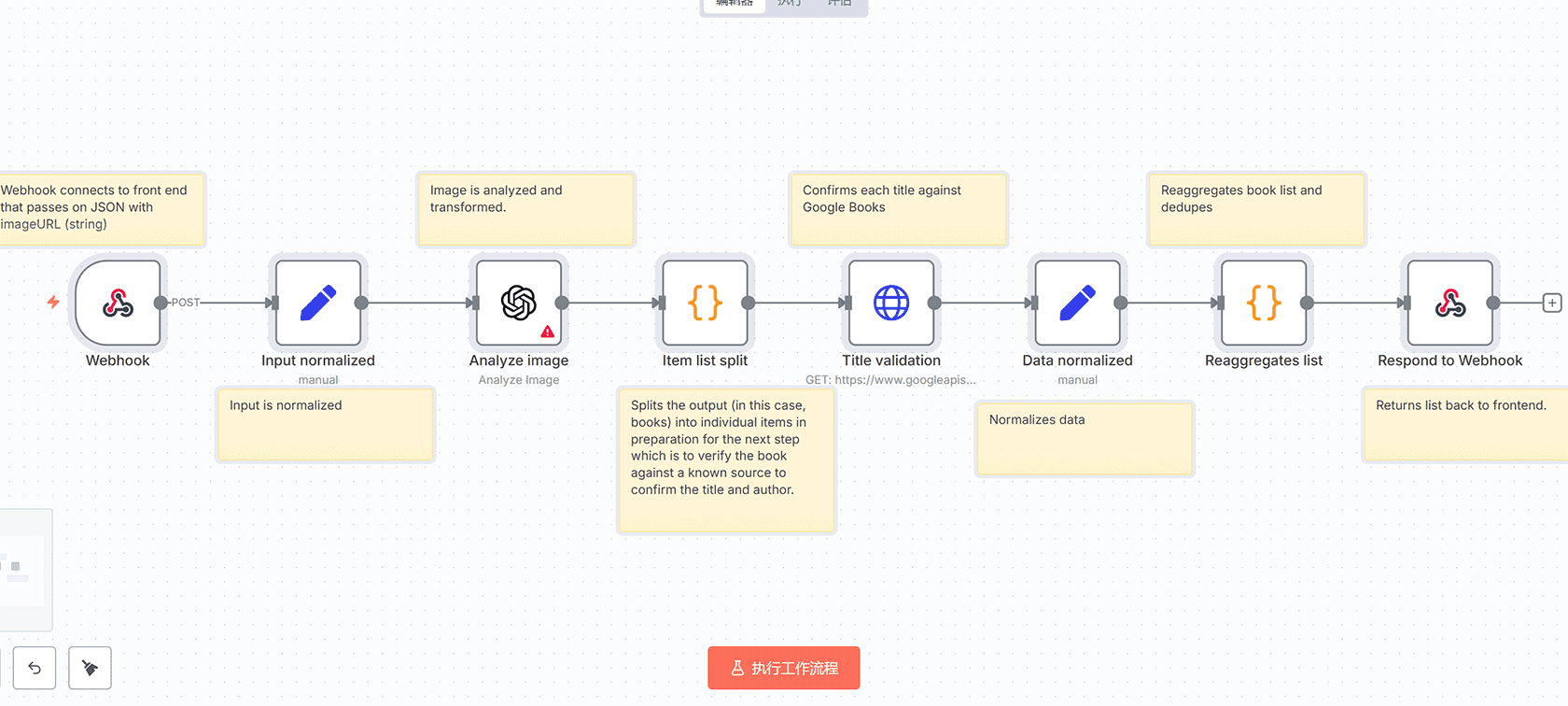
## 使用场景
分析包含多个主体的图像。在这个用例中,我们有一个书架,从书架照片中提取和验证书籍标题和作者信息。
## 工作原理
1. **Webhook接收图像URL**
– 从前端接收用户上传的图片URL
– 在这个用例中是书架图像
2. **输入标准化**
– Edit Field (Set)节点:将图像保存在一致的位置,便于AI查找
3. **图像分析**
– Analyze Image节点:分析图像内容
– 从书脊中提取标题信息
4. **数据拆分处理**
– Code节点:将提取的主体拆分为单个项目,以便单独验证每个项目
– 将书籍独立化为各自的实体
5. **标题验证**
– HTTP Request节点:验证每个主体
– 查询Google Books API验证书籍信息,以防只找到部分标题
6. **数据标准化**
– Edit Field (Set)节点:整理结果
7. **数据聚合与去重**
– Code节点:聚合和去重
– 将标题和作者汇总到列表中
8. **响应返回**
– Respond to Webhook节点:将列表返回给前端
## 使用方法
与能够捕获图像并接收结果的前端一起使用。在这个用例中,使用Supabase存储图像,图像分析器可以引用这些图像。
## 技术要点
– 使用GPT-4o-mini模型进行图像分析
– 通过Google Books API验证书籍信息
– 支持部分标题匹配和作者验证
– 自动去重和标准化输出格式
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。
评论(0)