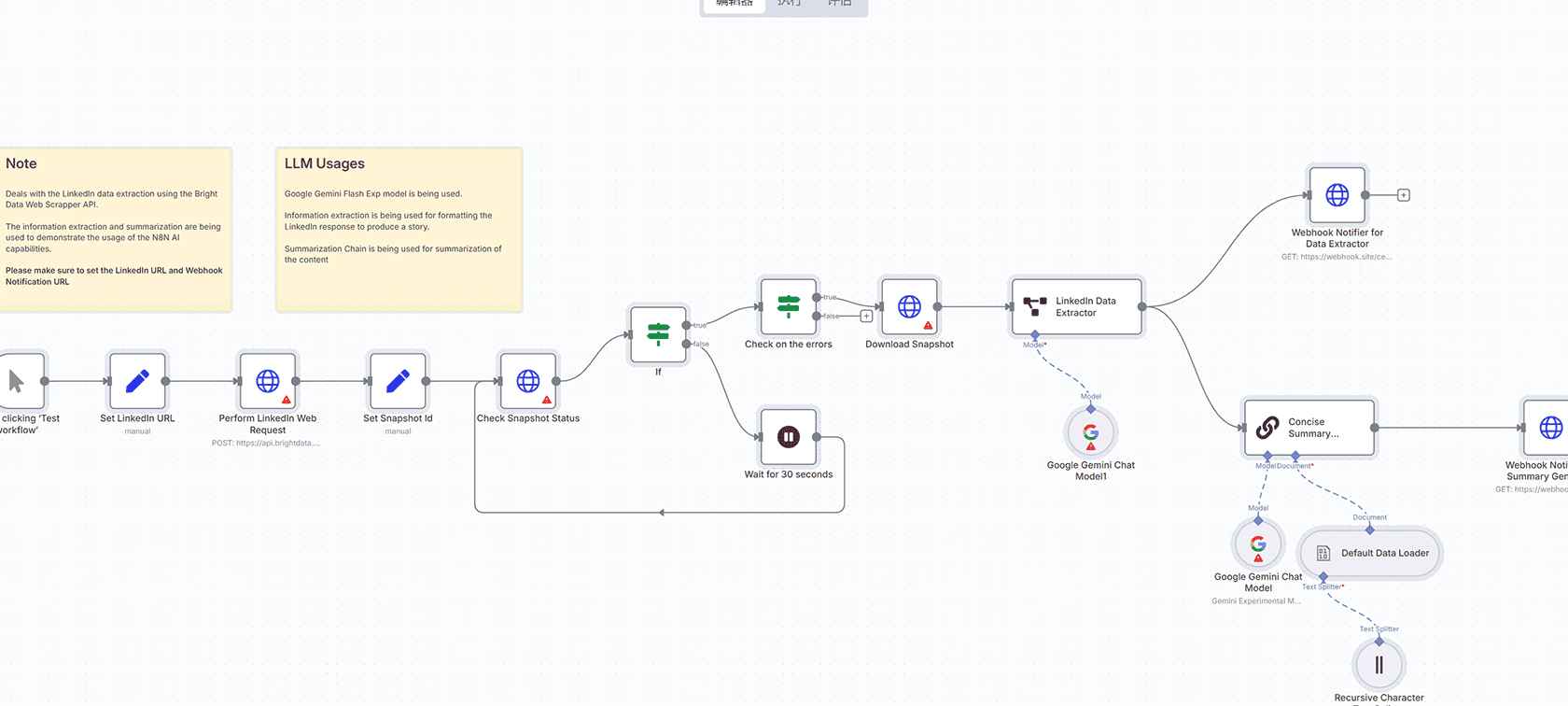
这个工作流是为谁设计的?
这个工作流专为开发者和数据科学家设计,他们希望高效地向Azure OpenAI批量API发送多个提示,并在单个批量过程中检索响应。它特别适用于需要处理大量文本数据的应用程序,如聊天机器人、内容生成或数据分析。
这个工作流解决了什么问题?
向Azure OpenAI API发送多个提示如果按顺序执行可能会很耗时且效率低下。这个工作流自动化了批量请求的过程,允许用户一次提交多个提示并以流线化的方式检索结果。这不仅节省时间,还优化了资源使用。
这个工作流做什么
这个工作流:
接受一个请求数组,每个请求包含一个提示和相关的参数。
将请求转换为适合批量处理的JSONL格式。
将批量文件上传到Azure OpenAI API。
创建一个批量作业来处理提示。
轮询作业状态并在处理完成后检索输出。
解析输出并返回结果。
Azure OpenAI批量API的关键特性
Azure OpenAI批量API旨在高效处理大规模和高容量的处理任务。关键特性包括:
异步处理:使用单独的配额处理请求组,目标是在比全球标准低50%的成本下实现24小时周转。
批量请求:在单个文件中发送大量请求,避免对在线工作负载造成干扰。
关键用例
大规模数据处理:快速并行分析广泛的数据集。
内容生成:创建大量文本,如产品描述或文章。
文档审查和摘要:自动化冗长文档的审查和摘要。
客户支持自动化:同时处理多个查询以实现更快的响应。
数据提取和分析:从大量非结构化数据中提取和分析信息。
自然语言处理(NLP)任务:在大数据集上执行情感分析或翻译等任务。
营销和个性化:大规模生成个性化内容和推荐。
设置
Azure OpenAI凭据:确保在n8n中设置了Azure OpenAI API凭据。
配置工作流:
在”Setup defaults”节点中设置az_openai_endpoint为您的Azure OpenAI端点。
如有必要,在”Set desired ‘api-version'”节点中调整api-version。
运行工作流:使用”Run example”节点触发工作流以查看其运行情况。
如何根据您的需求自定义此工作流
修改提示:更改”One query example”节点中的提示以适应您的应用程序。
调整参数:更新请求中的参数以自定义OpenAI模型的行为。
添加更多请求:您可以在输入数组中添加更多请求以处理额外的提示。
示例输入
[
{
“api-version”: “2025-03-01-preview”,
“requests”: [
{
“custom_id”: “first-prompt-in-my-batch”,
“params”: {
“messages”: [
{
“content”: “Hey ChatGPT, tell me a short fun fact about cats!”,
“role”: “user”
}
]
}
},
{
“custom_id”: “second-prompt-in-my-batch”,
“params”: {
“messages”: [
{
“content”: “Hey ChatGPT, tell me a short fun fact about bees!”,
“role”: “user”
}
]
}
}
]
}
]
示例输出
[
{
“custom_id”: “first-prompt-in-my-batch”,
“response”: {
“body”: {
“choices”: [
{
“message”: {
“content”: “Did you know that cats can make over 100 different sounds?”
}
}
]
}
}
},
{
“custom_id”: “second-prompt-in-my-batch”,
“response”: {
“body”: {
“choices”: [
{
“message”: {
“content”: “Bees communicate through a unique dance called the ‘waggle dance’.”
}
}
]
}
}
}
]
附加说明
作业管理:您可以随时取消作业,任何剩余的工作将被取消,而已完成的工作将被返回。您将需要为任何已完成的工作付费。
数据驻留:静态存储的数据保留在指定的Azure地理位置,而数据可能在任何Azure OpenAI位置进行推理处理。
指数退避:如果您的批量作业很大并达到排队令牌限制,某些区域支持使用指数退避排队多个批量作业。
此模板提供了一个全面的解决方案,用于使用Azure OpenAI批量API高效处理多个提示,使其成为开发者和数据科学家的宝贵工具。
评论(0)