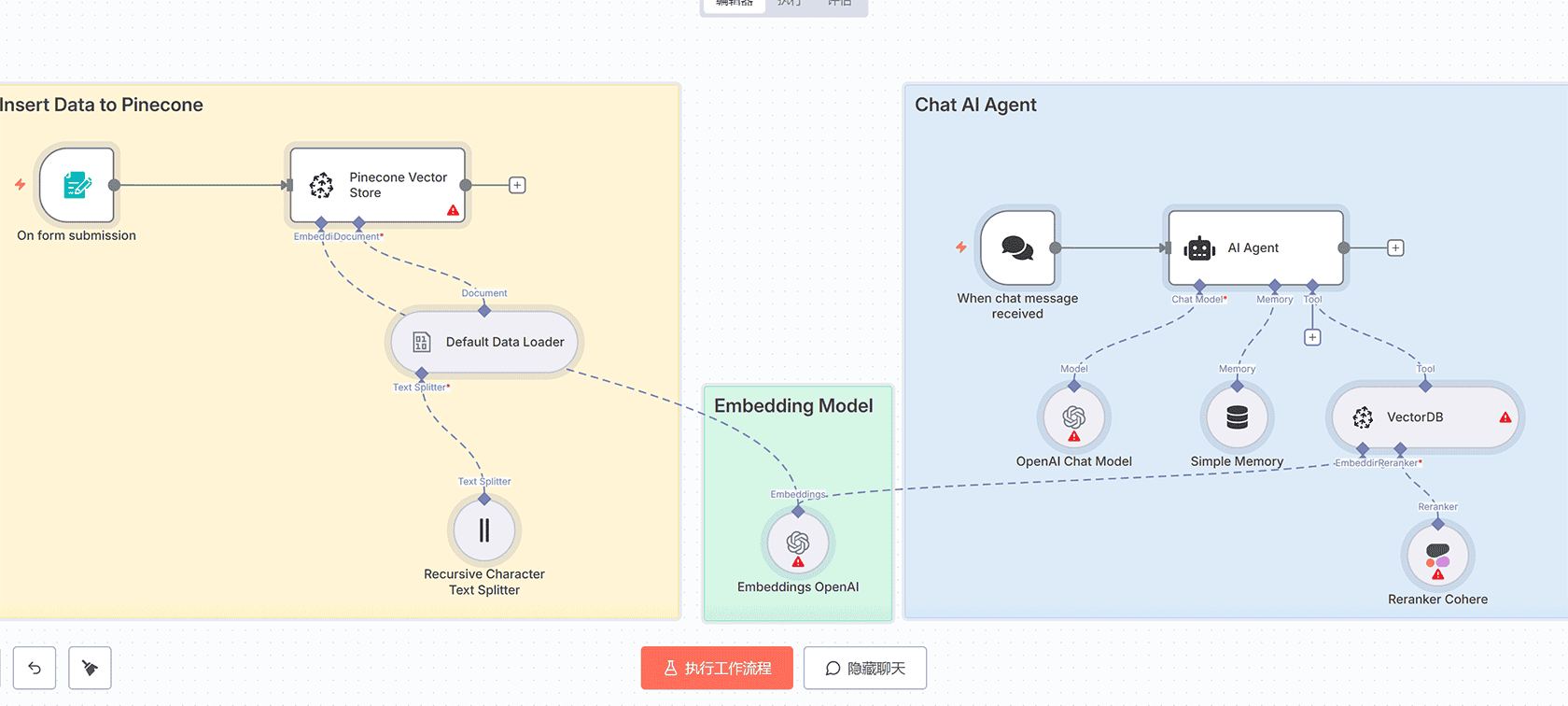
## 工作流概述
这个工作流提供了一个完整的检索增强生成(RAG)系统模板,能够构建强大的AI聊天机器人,基于您提供的PDF文档内容回答问题。它使用现代且强大的技术栈来实现最佳性能。
## 重要信息
**成本说明:** 此工作流使用付费服务(OpenAI、Pinecone、Cohere)。费用将根据您的使用量产生。请查看每个服务的定价页面以了解潜在费用。
**视频教程:** 有关此工作流功能的逐步指南,您可以观看随附的视频教程(印尼语):N8N教程:使用Pinecone、OpenAI和Cohere构建RAG聊天机器人
## 工作原理
此工作流在两个不同的阶段运行:
### 1. 数据摄取与索引
– 当通过n8n表单触发器上传.pdf文件时开始
– 默认数据加载器节点处理PDF,递归字符文本分割器将内容分解为更小、可管理的块
– Embeddings OpenAI节点将这些文本块转换为向量嵌入(数值表示)
– Pinecone向量存储节点获取这些嵌入并将其存储(更新)到您指定的Pinecone索引中,创建可搜索的知识库
### 2. 对话式AI代理
– 用户通过聊天触发器发送消息
– AI代理接收消息并使用其VectorDB工具搜索Pinecone索引以获取相关信息
– Reranker Cohere节点优化这些搜索结果,确保仅选择最相关的上下文
– 用户的原始问题和优化后的上下文被发送到OpenAI聊天模型(gpt-4.1),生成有帮助的、上下文感知的答案
– 简单内存节点维护对话历史,允许自然的多轮对话
## 使用方法
使用此工作流是一个两步过程:
1. **填充知识库:** 首先,您需要添加文档。使用表单触发器触发工作流并上传PDF文件。等待执行完成。您可以对多个文档执行此操作。
2. **开始聊天:** 一旦您的数据被摄取,打开聊天触发器的界面并开始询问与您上传文档内容相关的问题。
表单触发器只是一个示例。请随意将其替换为其他触发器,例如监视Google Drive或Dropbox文件夹中新文件的节点。
## 要求
要运行此工作流,您需要以下服务的活跃账户和API密钥:
– **OpenAI账户和API密钥:**
– 功能:为文本嵌入和最终聊天生成提供支持
– 需要用于Embeddings OpenAI和OpenAI Chat Model节点
– **Pinecone账户和API密钥:**
– 功能:用于存储和检索您的向量知识库
– 需要用于Pinecone Vector Store和VectorDB节点。您还需要提供Pinecone环境
– **Cohere账户和API密钥:**
– 功能:通过重新排序搜索结果以提高相关性来改进聊天机器人的准确性
– 需要用于Reranker Cohere节点
## 自定义此工作流
此模板是一个很好的起点。以下是几种自定义方式:
– **更改AI个性:** 编辑AI代理节点中的系统消息以更改机器人的行为、语气或指令
– **使用不同模型:** 您可以在OpenAI Chat Model节点中轻松将OpenAI模型替换为另一个模型(例如,gpt-3.5-turbo以降低成本)
– **调整检索:** 在VectorDB工具节点中,您可以修改Top K参数以检索更多或更少的文档块用作上下文
– **自动化摄取:** 将手动表单触发器替换为自动化触发器,例如每当新文件添加到特定云存储文件夹时触发的节点
评论(0)