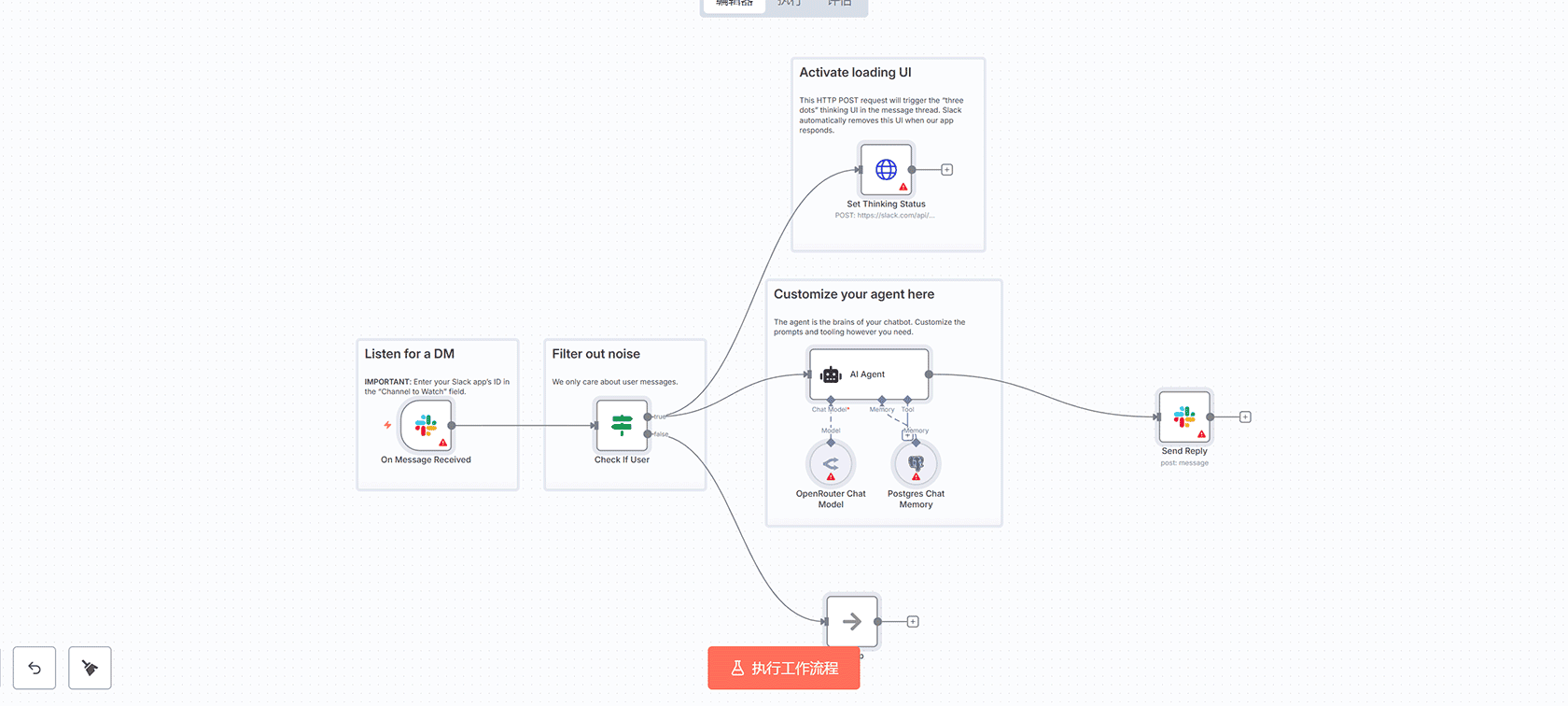
## 工作流概述
这个n8n工作流利用InfraNodus GraphRAG技术,通过分析上传的PDF文档内容,识别知识图谱中的结构空白,并自动生成具有创新性的研究问题和思路。
## 工作流程步骤
### 第1步:用户上传PDF文件
– 通过表单触发器接收用户上传的PDF文件
– 可公开暴露端点供组织内使用
### 第2步:二进制文件转换为PDF
– 将上传的二进制文件转换为PDF格式
– 为后续文本提取做准备
### 第3步:从PDF文件中提取文本
– 使用Extract From File节点提取PDF中的纯文本
– 可选:使用ConvertAPI进行更高质量的文本提取,保持原始文档格式
### 第4步:组合提取的文本
– 将所有提取的文本合并为一个文本字符串
– 为InfraNodus准备数据
– 指定InfraNodus生成建议时使用的空白深度
### 第5步:使用InfraNodus GraphRAG构建知识图谱
– InfraNodus从所有文本构建知识图谱
– 识别连接最少的主题集群
– 生成能够以新方式连接这些集群的研究问题
### 第6步:使用InfraNodus GraphRAG API生成响应
– 使用上一步生成的空白问题
– 基于PDF文档生成创新思路
– 需要提供InfraNodus API密钥
### 第7步:向用户显示问题/提示
– 在表单中显示生成的问题和响应
– 可选:通过webhook暴露或在自己的应用中使用iframe显示
## 可选功能
### 更好的PDF转换
– 使用ConvertAPI替代标准PDF到文本转换
– 保持原始文档布局,不将段落切割为短片段
### 从不同论文集合获取答案
– 使用不同的PDF集合生成答案
– 特别适用于跨学科研究
– 可使用现有的InfraNodus”专家”图谱
## InfraNodus GraphRAG工作原理
InfraNodus GraphRAG通过分析文本结构来避免通用响应和LLM偏见:
1. **构建知识图谱**:将文本表示为概念和关系的网络
2. **识别结构空白**:识别在同一上下文中出现但连接不良的概念集群
3. **生成创新问题**:使用AI生成连接这些空白的问题/提示
## 技术特点
– **避免通用响应**:通过结构分析生成独特的研究问题
– **跨学科整合**:支持不同文档集合的交叉分析
– **高质量文本处理**:支持ConvertAPI等高级转换工具
– **灵活的部署选项**:支持webhook集成和自定义应用嵌入
评论(0)