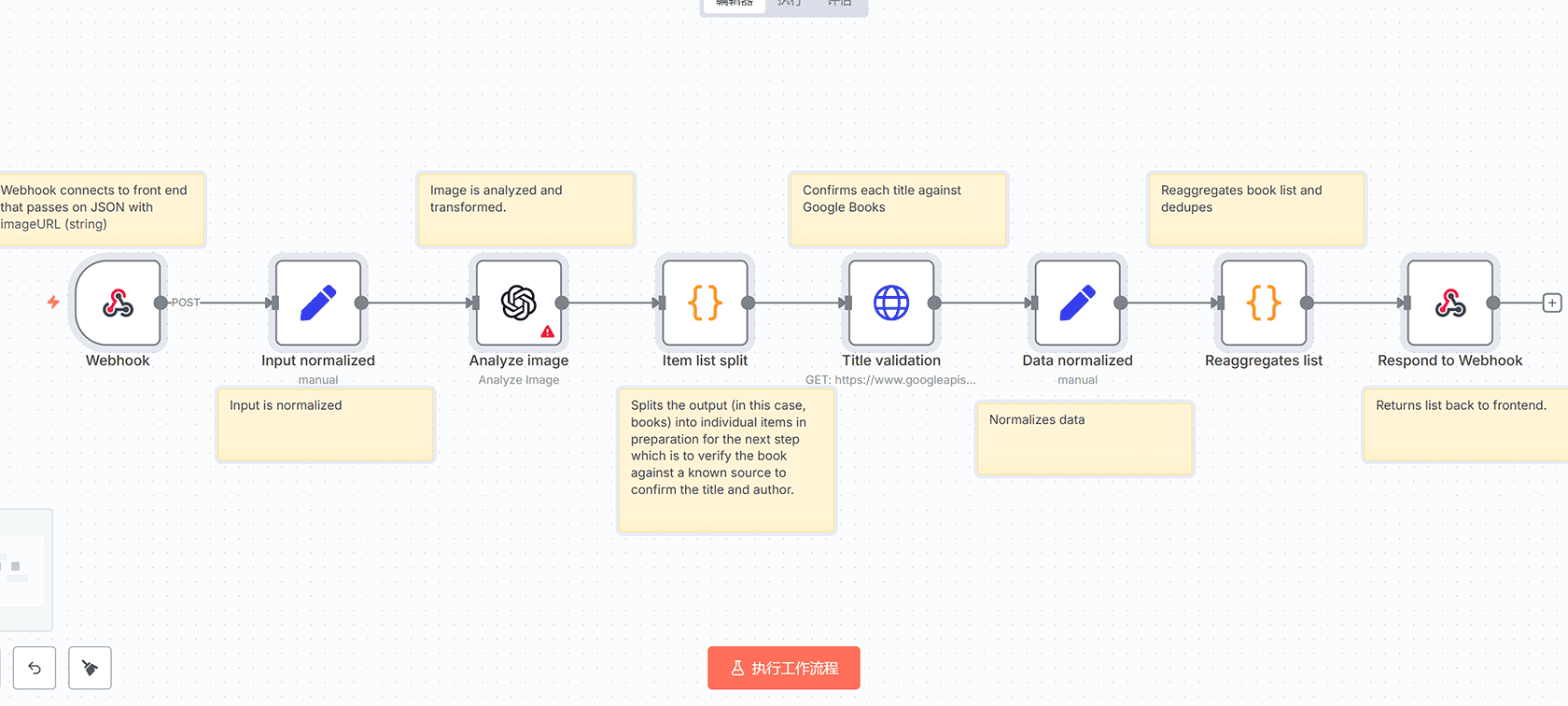
## 工作流概述
这个n8n工作流是一个智能图书扫描系统,能够通过AI技术自动识别书籍封面图像中的书名和作者信息,并通过Google Books API进行验证,最终返回结构化的书籍数据。
## 工作流流程
### 1. 数据输入与预处理
– **Webhook节点**:接收前端传递的JSON数据,包含书籍封面图像的URL
– **Set节点(Input normalized)**:对输入数据进行标准化处理,提取并清理图像URL字段
### 2. AI图像分析
– **OpenAI节点(Analyze image)**:使用GPT-4o-mini模型分析书籍封面图像
– 严格解析规则:只提取清晰可见的书名和作者信息,不进行猜测
– 输出标准化JSON格式:{“books”:[{“title”:”书名”,”author”:”作者|null”}]}
### 3. 数据处理与拆分
– **Code节点(Item list split)**:将AI分析结果拆分为单个书籍项目
– 清理代码块标记和格式化数据
– 为搜索查询准备辅助字段
### 4. 数据验证
– **HTTP Request节点(Title validation)**:调用Google Books API验证书籍信息
– 使用”intitle”和”inauthor”参数进行精确搜索
– 限制结果数量为5条,按相关性排序
### 5. 数据标准化与聚合
– **Set节点(Data normalized)**:标准化验证后的书籍数据
– **Code节点(Reaggregates list)**:重新聚合书籍列表并去重
### 6. 结果返回
– **Respond to Webhook节点**:将最终验证的书籍列表返回给前端
– 设置HTTP状态码200和JSON响应格式
## 技术特点
– **多模态AI集成**:结合计算机视觉和自然语言处理技术
– **数据验证机制**:通过权威API确保数据准确性
– **容错处理**:完善的错误处理和数据清理机制
– **标准化输出**:统一的JSON数据格式
## 应用场景
– 图书馆数字化管理
– 个人图书收藏管理
– 书店库存管理系统
– 学术研究数据收集
评论(0)