## 概述
研究人员和学术机构需要高效处理和分析大量研究论文和学术文档的方法,包括扫描的PDF和基于图像的材料(JPG、PNG)。手动审查学术文献耗时且难以识别趋势、跟踪引用和综合多篇论文的发现。此工作流使用OCR技术自动提取和分析研究论文和扫描文档,从数字和基于图像的来源创建可搜索的学术见解知识库。
## 功能特点
– 从研究论文中自动提取关键信息,包括方法、发现和引用
– 从数字和基于图像的来源构建可搜索的学术见解数据库
– 跟踪引用并识别多篇论文的研究趋势
– 高效综合大量学术文献的发现
## 目标用户
研究机构、大学图书馆、研发部门、学术研究人员、文献综述团队以及跟踪其领域科学发展的组织。
## 解决的问题
文献综述需要阅读数百篇论文以识别相关发现和方法。此模板自动从研究论文中提取关键信息,包括方法、发现和引用。它构建了一个可搜索的数据库,帮助研究人员快速找到相关研究并识别研究空白。
## 设置说明
– 安装具有学术功能的PDF Vector社区节点
– 配置启用学术搜索的PDF Vector API
– 配置Google Drive凭据以访问文档
– 设置数据库以存储提取的研究数据
– 配置引用跟踪偏好
– 设置从来源自动摄入论文
– 配置摘要生成参数
## 关键功能
– Google Drive集成以检索研究论文(PDF、JPG、PNG)
– 扫描文档和图像的OCR处理
– 从任何格式自动提取论文元数据和结构
– 从PDF和图像中总结方法和发现
– 引用网络分析和指标
– 多论文趋势识别
– 创建可搜索的研究数据库
– 与学术搜索引擎集成
## 自定义选项
– 添加特定领域的提取模板
– 配置从arXiv、PubMed等自动发现论文
– 实现引用警报系统
– 创建研究趋势可视化
– 为研究团队添加协作功能
– 为研究查询构建API端点
– 与参考管理工具集成
## 实施细节
工作流使用PDF Vector的学术功能来理解研究论文结构并提取有意义的见解。它处理来自各种来源的论文,识别关键贡献,并创建结构化摘要。系统跟踪引用以衡量影响,并通过分析领域中的多篇论文来识别新兴研究趋势。
注意:此工作流使用PDF Vector社区节点。在使用此模板之前,请确保从n8n社区节点集合中安装它。
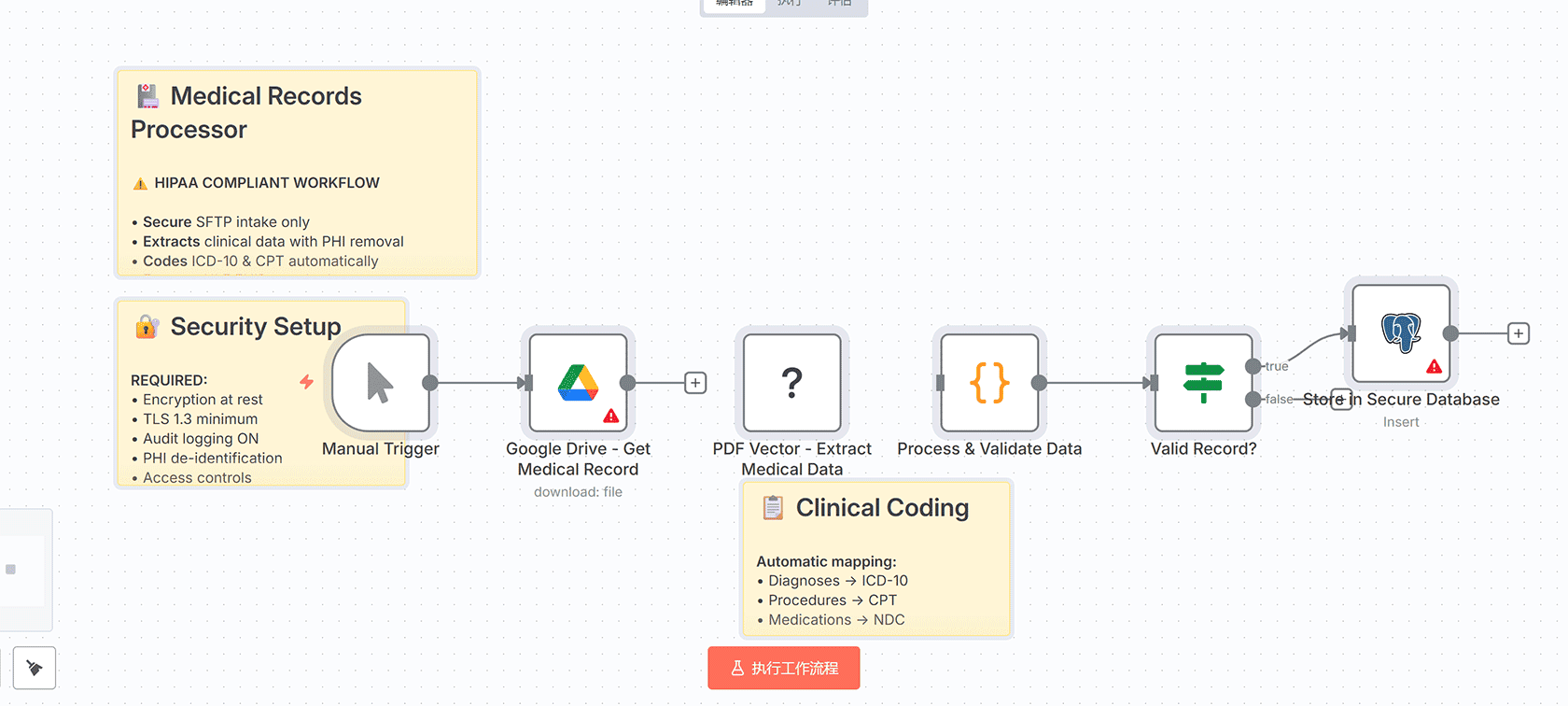
## 工作流节点结构
此工作流包含以下主要节点:
1. **Manual Trigger** – 手动触发处理收据
2. **Google Drive** – 从Google Drive获取收据文件
3. **PDF Vector – Extract Receipt** – 使用OCR技术提取收据数据
4. **PDF Vector – Tax Categorization** – 税务分类和可抵扣性分析
5. **Process Expense Data** – 验证和处理费用数据
6. **Save to Expense Sheet** – 将结果保存到Google Sheets
工作流通过粘性笔记提供清晰的流程说明:
– Receipt Overview:概述自动化费用管理功能
– Input Sources:处理所有输入格式
– Tax Categories:自动税务分类逻辑
## 技术特点
– 支持多种收据格式:手机照片、扫描PDF、邮件转发、低质量图像
– 使用OCR技术增强图像识别
– 自动税务分类:差旅费用、办公用品、餐饮(50%抵扣)、公用事业
– 财务计算验证和一致性检查
– 与QuickBooks同步
评论(0)