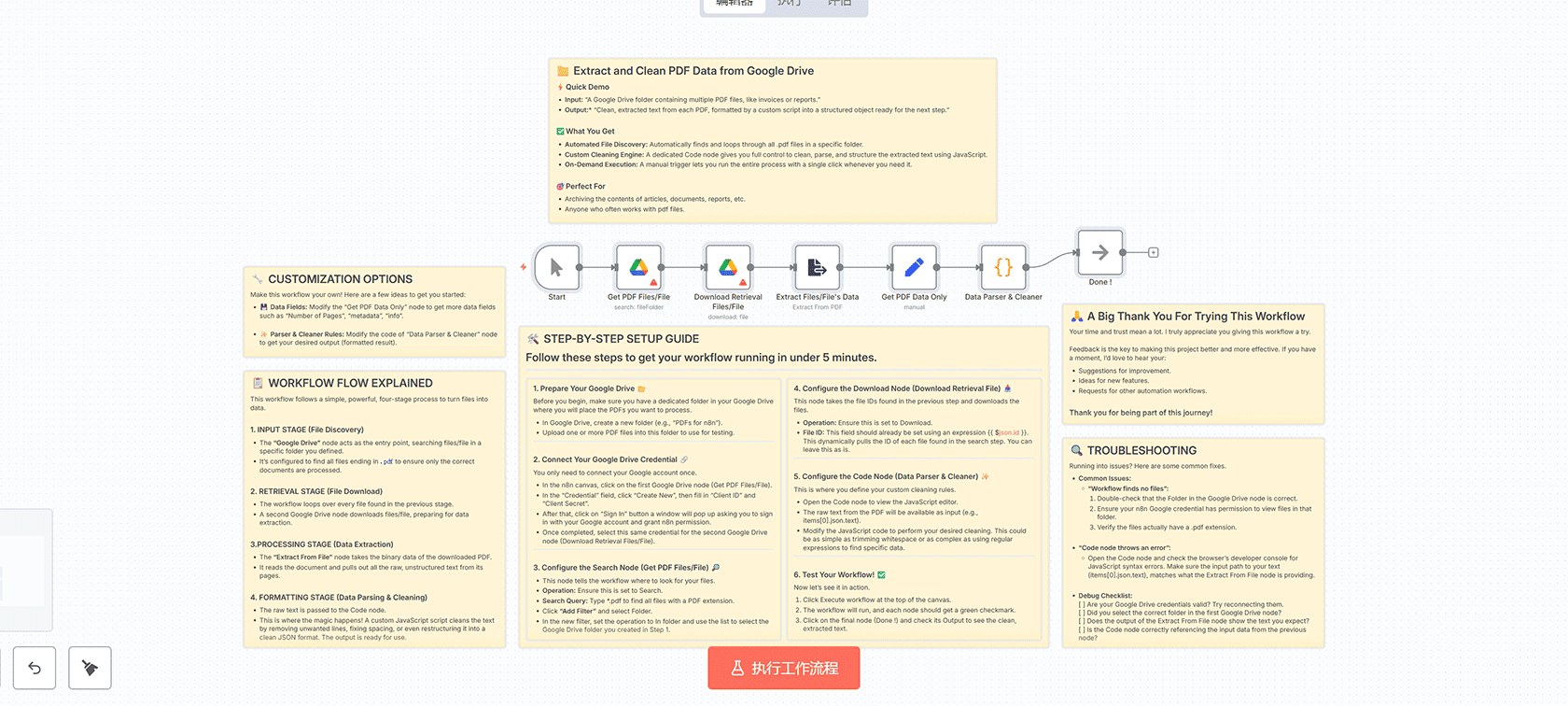
## 概述
这个n8n工作流能够自动从Google Drive文件夹中提取PDF文件,并清理提取的文本内容。通过自定义JavaScript脚本,您可以完全控制数据的清理和格式化过程,将原始PDF文本转换为结构化的数据格式。
## 工作流程如何运作
### 1. 输入阶段(文件发现)
– **Google Drive节点**作为入口点,在您定义的特定文件夹中搜索PDF文件
– 配置为查找所有以`.pdf`结尾的文件,确保只处理正确的文档
### 2. 检索阶段(文件下载)
– 工作流循环处理在前一阶段找到的每个文件
– 第二个Google Drive节点下载文件,为数据提取做准备
### 3. 处理阶段(数据提取)
– **Extract From File节点**获取下载的PDF的二进制数据
– 读取文档并从其页面中提取所有原始的、非结构化的文本
### 4. 格式化阶段(数据解析和清理)
– 原始文本传递给Code节点
– 自定义JavaScript脚本清理文本,删除不需要的行,修复间距,甚至将其重新构建为干净的JSON格式
## 设置步骤
### 准备工作
1. 在Google Drive中准备一个专用文件夹,用于存放要处理的PDF文件
2. 上传一个或多个PDF文件到此文件夹进行测试
### 配置Google Drive凭据
– 在n8n画布中,点击第一个Google Drive节点
– 在”凭据”字段中,点击”创建新凭据”
– 填写”客户端ID”和”客户端密钥”
– 点击”登录”按钮,使用您的Google账户登录并授予n8n权限
### 配置搜索节点
– 确保操作设置为”搜索”
– 在搜索查询中输入`*.pdf`以查找所有PDF扩展名的文件
– 点击”添加过滤器”并选择”文件夹”
– 在新过滤器中,将操作设置为”在文件夹中”,并选择您在步骤1中创建的Google Drive文件夹
### 配置下载节点
– 确保操作设置为”下载”
– 文件ID字段应已使用表达式`{{ $json.id }}`设置,这会动态提取搜索步骤中找到的每个文件的ID
### 配置代码节点
– 打开Code节点查看JavaScript编辑器
– 来自PDF的原始文本将作为输入可用
– 修改JavaScript代码以执行所需的清理操作
## 自定义选项
### 数据字段
– 修改”Get PDF Data Only”节点以获取更多数据字段,如”页数”、”元数据”、”信息”等
### 解析器和清理规则
– 修改”Data Parser & Cleaner”节点的代码以获得所需的输出(格式化结果)
## 故障排除
### 常见问题
– **”工作流找不到文件”**:
1. 双重检查Google Drive节点中的文件夹是否正确
2. 确保您的n8n Google凭据有权查看该文件夹中的文件
3. 验证文件是否确实具有.pdf扩展名
– **”代码节点抛出错误”**:
– 打开Code节点并检查浏览器的开发者控制台以查找JavaScript语法错误
– 确保输入路径到您的文本与Extract From File节点提供的内容匹配
### 调试清单
– [ ] 您的Google Drive凭据是否有效?尝试重新连接它们
– [ ] 您是否在第一个Google Drive节点中选择了正确的文件夹?
– [ ] Extract From File节点的输出是否显示您期望的文本?
– [ ] Code节点是否正确引用了来自前一节点的输入数据?
评论(0)