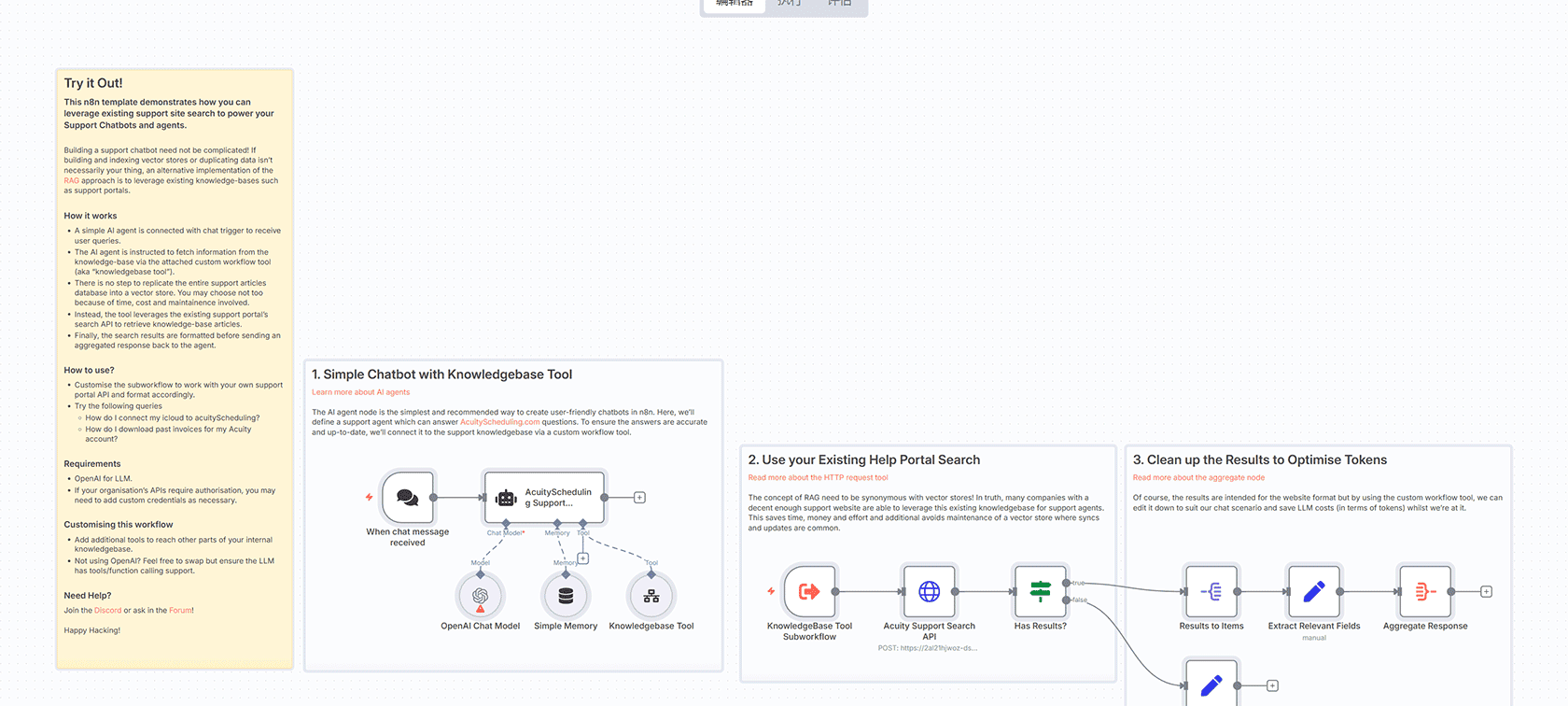
🧠 这个工作流专为一个目的设计:从FTP服务器批量上传结构化的JSON文章到Qdrant向量数据库,用于LLM驱动的语义搜索、RAG系统或AI助手。
JSON文件已经预先清理并包含元数据和富文本块,准备进行向量化。这个工作流处理:
从FTP下载
解析和分割
使用OpenAI嵌入进行向量化
存储在Qdrant中供未来查询
博客文章的JSON结构格式
{
“id”: “article_001”,
“title”: “reseguider”,
“language”: “sv”,
“tags”: [“london”, “resa”, “info”],
“source”: “alltomlondon.se”,
“url”: “https://…”,
“embedded_at”: “2025-04-08T15:27:00Z”,
“chunks”: [
{
“chunk_id”: “article_001_01”,
“section_title”: “Introduktion”,
“text”: “Välkommen till London…”
},
…
]
}
🧰 优势
✅ 自动化向量加载
处理FTP → JSON → Qdrant的无手动管道。
✅ 干净的嵌入输入
支持预先验证的块,包含元数据:标题、标签、语言和文章ID。
✅ AI就绪格式
非常适合检索增强生成(RAG)、语义搜索或助手记忆。
✅ 灵活架构
模块化和可替换:FTP可以替换为GDrive/Notion/S3,嵌入可以切换到本地模型如Ollama。
✅ 社区友好
这个模板帮助其他人采用向量数据库喂养和LLM集成的最佳实践。
评论(0)